
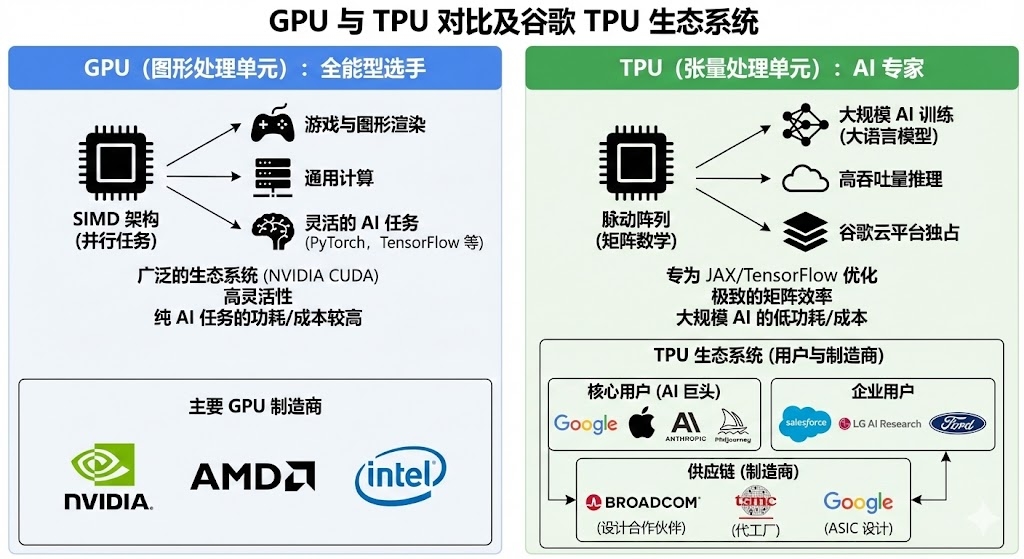
这是关于Google TPU(张量处理单元)与NVIDIA GPU(图形处理单元)的深度对比。
简而言之:GPU 是“全能型选手”,灵活且生态成熟;TPU 是“专用型专家”,在特定的大规模矩阵运算(如深度学习训练)中效率极致。
1. 核心定位与架构差异 (Architecture)
这是两者最根本的区别,决定了它们各自擅长的领域。
| 特性 | GPU (Graphics Processing Unit) | TPU (Tensor Processing Unit) |
|---|---|---|
| 设计初衷 | 最初为图形渲染设计,后演变为通用并行计算(GPGPU)。 | 专为机器学习(特别是深度学习)设计的定制ASIC芯片。 |
| 核心架构 | SIMD(单指令多数据):拥有数千个较小的核心(如CUDA Cores),擅长同时处理大量并行的独立任务。 | 脉动阵列 (Systolic Array):核心是大规模矩阵乘法单元 (MXU)。数据像血液在心脏中流动一样,在芯片内部有序流动并被复用。 |
| 灵活性 | 极高。除了AI,还能做图形渲染、物理模拟、科学计算等。支持各种精度(FP64, FP32, FP16, INT8)。 | 较低。高度专注于矩阵乘法和卷积运算。通常针对低精度(如 bfloat16)进行了极致优化。 |
| 缓存机制 | 需要频繁从内存(DRAM)读取数据,虽然带宽很高,但访问内存仍是瓶颈。 | 极度减少内存访问。数据一旦从内存加载,就在阵列中逐级传递,最大化复用,大幅降低延迟和能耗。 |
比喻:
- GPU 像是一个拥有几千个普通数学家的团队,每个人拿一张纸计算,算完交给下一个。适合所有人一起做类似的题。
- TPU 像是一条精密的流水线工厂。原材料(数据)放进去,经过一连串固定的加工步骤,不需要中间反复搬运,直接出产品。做特定产品(矩阵运算)极快,但改生产线(非标准算法)很难。
2. 性能与效率 (Performance & Efficiency)
训练速度 (Training):
- TPU 在处理大规模模型(如 Transformer 架构、BERT、ResNet)和超大批量(Batch Size)数据时,往往比同代 GPU 更快。TPU Pod(集群)通过高速互联(ICI)可以轻松扩展到数千个芯片,线性加速比极佳。
- GPU 在小批量、非标准网络结构或需要频繁控制流(Control Flow)的任务上表现更好。
推理 (Inference):
- TPU 的推理延迟极低,吞吐量大,非常适合高并发的实时服务。
- GPU(特别是 NVIDIA 的 T4, A10, L4 等推理卡)也非常强大,且由于其通用性,部署起来往往更灵活。
能效比 (Performance per Watt):
- TPU 完胜。因为砍掉了图形渲染等不需要的硬件逻辑,TPU 在单位能耗下能提供更高的算力(FLOPS),这对大规模数据中心极其重要。
3. 生态系统与开发难度 (Ecosystem)
这是 GPU 目前最大的护城河。
GPU (NVIDIA CUDA):
- 垄断级生态。几乎所有的深度学习框架(PyTorch, TensorFlow, MXNet等)都优先且完美支持 GPU。
- 社区资源极其丰富,遇到问题随便一搜就有解决方案。
- 可以在任何地方使用:自己的电脑、AWS、Azure、GCP、阿里云等。
TPU (Google Cloud):
- 强绑定 Google 生态。主要通过 TensorFlow 和 JAX 使用。虽然 PyTorch 也有
PyTorch/XLA支持,但相比原生的 CUDA 支持,坑稍多一些,调试难度较大。 - 云端独占。你买不到实体的 TPU 显卡插在电脑上,只能在 Google Cloud Platform (GCP) 上租赁使用(或者通过 Colab 使用免费额度)。
- 强绑定 Google 生态。主要通过 TensorFlow 和 JAX 使用。虽然 PyTorch 也有
4. 成本 (Cost)
- GPU: 价格昂贵(特别是 H100/A100 等高端卡),且受供需关系影响大(缺货时溢价严重)。但在本地组建算力时,GPU 是唯一选择。
- TPU: Google 通常提供具有竞争力的性价比。特别是 Spot 实例(抢占式),价格可能非常低。对于需要长时间训练的大模型,TPU 往往能节省大量云服务账单。
| 场景 | 推荐选择 | 原因 |
|---|---|---|
| 刚入门 / 学习 / 研究 | GPU | 教程多,PyTorch 代码拿来即跑,调试方便,通用性强。 |
| 小规模实验 / 个人项目 | GPU | 灵活性高,不需要修改代码适配硬件。 |
| 大规模模型训练 (LLM) | TPU (或高端GPU集群) | 数据量巨大时,TPU 的线性扩展能力和性价比优势明显。 |
| 使用 TensorFlow/JAX | TPU | 原生支持极好,能榨干硬件性能。 |
| 使用 PyTorch 且不想折腾 | GPU | CUDA 生态最成熟,无需处理 XLA 编译器的兼容性问题。 |
| 需要本地部署 / 边缘计算 | GPU | TPU 无法购买实体硬件(除 Edge TPU 外,但那是另一回事)。 |
目前使用 Google TPU(张量处理单元)的“厂家”主要分为两类:一类是直接使用 TPU 进行模型训练和推理的科技公司与 AI 机构(这是最常见的理解),另一类是参与 TPU 制造产业链的硬件厂商。
以下是详细名单和分析:
5. 核心用户:顶级科技巨头与 AI 独角兽
这部分公司主要通过 Google Cloud 租赁 TPU 算力,用于训练其核心大模型。
Apple (苹果公司)
- 重磅案例:Apple 在其技术论文中正式披露,Apple Intelligence(苹果智能)的基础模型是在 Google 的 TPUv4 和 TPUv5 集群上进行预训练的,而非单纯依赖 NVIDIA GPU。这是 TPU 证明其性能与稳定性的最强背书之一。
Anthropic
- 核心盟友:作为 OpenAI 的最强竞争对手(Claude 系列模型开发商),Anthropic 是 Google TPU 的深度用户。Google 向其投资并与其签署了大规模云计算协议,Anthropic 使用大量 TPUv5e 和 TPUv5p 来训练 Claude 3 等前沿模型。
Midjourney
- AI 绘画巨头:知名的 AI 绘画工具 Midjourney 的模型训练和推理算力主要由 Google Cloud TPU 提供。TPU 在处理这种大规模生成式任务时具有极高的性价比。
Hugging Face
- 开源社区枢纽:作为 AI 领域的“GitHub”,Hugging Face 与 Google 合作,使其平台上的开源模型能够更轻松地在 TPU 上运行,并利用 TPU 进行优化训练。
Character.AI
- AI 社交:由前 Google 员工创立的独角兽公司,主要利用 Google Cloud TPU 来驱动其数百万用户的高并发实时对话服务。
Google (自身)
最大用户:Google 内部几乎所有产品都依赖 TPU。
- Gemini / PaLM 模型:完全在 TPU 上训练。
- 搜索 (Search):用于理解查询语义(BERT/RankBrain)。
- Waymo:自动驾驶的数据处理和模型训练。
- Google Photos/Translate:图像识别和实时翻译。
6. 企业与行业应用
这些传统行业的公司利用 Google Cloud 上的 TPU 算力来解决特定的业务问题。
- Salesforce:利用 TPU 训练其企业级 AI 模型(Einstein)。
- LG AI Research:韩国 LG 集团的 AI 研究院,使用 TPU 训练其超大规模多模态模型 EXAONE。
- Ford (福特汽车):在自动驾驶和数据分析领域与 Google 合作,利用 TPU 加速模拟和计算。
- Kakao Brain:韩国互联网巨头 Kakao 旗下的 AI 部门,使用 TPU 训练韩语大模型。
7. 产业链:谁在“制造”TPU?
如果您所说的“厂家”是指生产 TPU 芯片的硬件供应链厂商,名单如下:
- Google:负责核心架构设计(ASIC 设计)。
- Broadcom (博通):关键的合作伙伴。协助 Google 进行芯片的物理设计、IP 授权以及与代工厂的对接(负责将设计转化为可制造的图纸)。
- TSMC (台积电):负责芯片的实际晶圆代工(制造)。例如 TPUv4 使用了台积电的 7nm 工艺,最新的 Trillium (TPUv6) 和 TPUv5p 则采用更先进的工艺(如 5nm/4nm)。
- 世芯-KY (Alchip) / 联发科 (MediaTek):部分传闻和供应链分析指出,随着 TPU 迭代,除了博通外,台湾的 ASIC 设计服务商也可能参与部分后端设计或周边芯片开发。
总结
| 类别 | 代表公司/机构 | 用途 |
|---|---|---|
| 超级大厂 | Apple, Google | 训练核心基础模型 (Apple Intelligence, Gemini) |
| AI 独角兽 | Anthropic, Midjourney, Character.AI | 训练与推理 LLM 及生成式模型 |
| 企业用户 | Salesforce, LG, Ford | 垂直领域应用、研发 |
| 制造方 | Broadcom, TSMC | 协助设计与芯片代工 |
