
本文根据下面的英文文章由AI总结整理。
这篇文章的核心观点可以概括为一句话:“Vibe coding”不是在学编程语言,而是在学如何用足够清晰、可执行的方式,把需求委托给 AI,并用小步迭代把东西真正跑起来。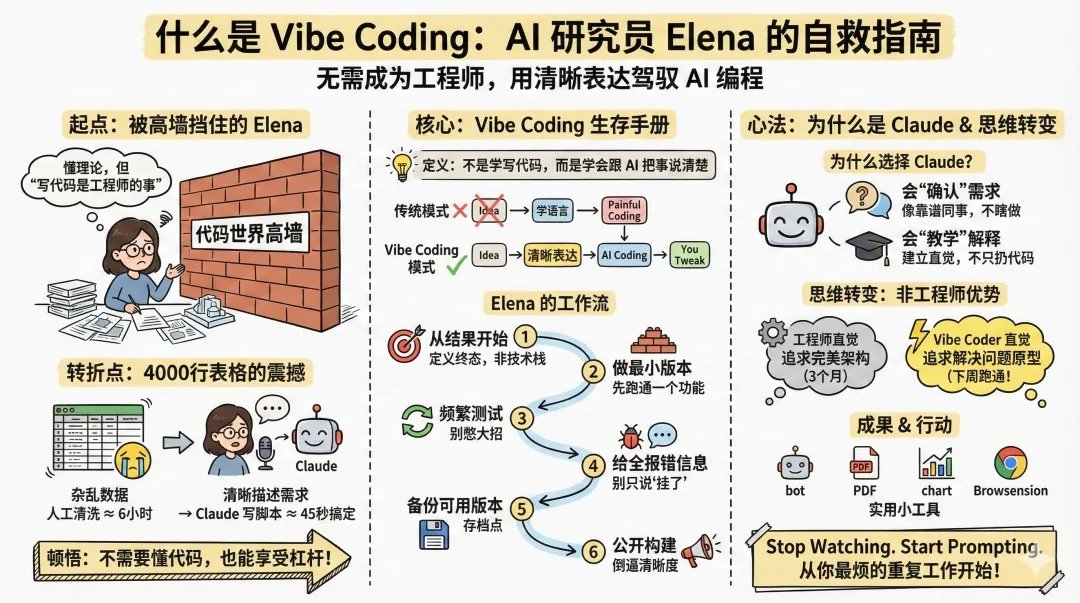
下面按文章结构总结其主要观点(含作者给出的实践方法论):
1) Vibe coding 的本质:沟通能力,而非编码能力
- 作者认为,很多人以为 vibe coding 是“学会写代码”,但真正的关键是把目标描述清楚。
- AI(文中主要是 Claude)像一个“非常聪明但不了解你业务上下文的实习生”:如果你只说“做个 X”,它只能猜,猜得越多,越容易偏离。
2) 失败的常见原因:提示词太“懒”、让模型读心
- 典型失败提示:例如“帮我做个邮件工具”“它不工作了,修一下”。
- 典型成功提示:明确输入、处理规则、边界条件、输出格式、统计口径(例如:读 CSV、用正则校验邮箱、按某列去重、输出新 CSV,并打印处理/无效/重复数量)。
3) 最重要的工程化习惯:不要一次做完整系统,要拆成可验证的小步骤
- 作者踩坑:试图一次性做“Twitter 书签分析器”导致依赖复杂、报错难排、最终放弃。
复盘后的正确做法:把大任务拆成最小可运行单元,逐步追加功能,例如:
- 先拉取最近 100 条书签
- 再抽取文本
- 再分类
- 再存 JSON
- 核心原则:每一步先跑通,再加下一步,scope(范围)比“能力”更决定能否交付。
4) 为什么作者更偏向 Claude:会澄清、会解释
作者并不认为 Claude 代码一定更强,而是:
- Claude 更倾向于先问清楚再写,减少“自信但错误”的实现。
- Claude 会额外解释关键决策,帮助非工程背景的人边做边学。
- 相比之下,作者认为某些工具(如偏 IDE 的方案)更适合已有工程经验的人,因为默认你能理解项目结构和惯例。
5) 作者的“可复用工作流”
作者总结了一个可复制的流程,用于把“想法”落地为可运行的东西:
- 从结果出发,不先限定技术栈(先说要什么结果,让模型选工具)。
- 拆到最小第一步并立即运行验证。
- 每 20–30 行就测试一次,避免积累大故障面。
- 出错时给足上下文:完整报错、相关代码片段、预期 vs 实际。
- 经常保存可用版本,避免一次改动毁掉整个进度。
- 如果可能,公开分享构建过程以获得反馈,加速学习。
6) Vibe coding 能做什么:80% 的“实用工具”足够了
- 作者给的例子集中在自动化、爬虫、数据处理、Bot、浏览器插件、内部报表工具、价格追踪等。
- 结论是:这些东西不一定“改变世界”,但能显著省时间/省钱;过去可能需要外包,现在可以自己在一个下午做出来。
7) 对工程师与“vibe coder”的定位:原型与非关键系统优势明显
- 作者强调:vibe coding 并不意味着“非工程师比工程师强”。
- 对复杂、关键、可靠性要求高的系统,仍需要懂底层的人把关。
- 但对大量内部工具和轻量产品,市场更看重“交付速度与可用性”,清晰表达并快速迭代的人可以更快产出可用原型。
8) 如何开始:从一个真实、重复、讨厌的小任务入手
- 不从宏大创业点子开始,而是从一个日常耗时的手工流程开始。
- 用“输入-处理-输出”的方式把需求写清楚,运行、报错、补充信息、迭代,直到可用,再逐步加功能。
- 作者的收束句:“差距变小了,别只看,开始 prompt。”
如果你愿意,我可以把这篇文章的要点进一步提炼成一页“vibe coding 提示词模板”(适合你做数据分析、报表自动化、脚本工具的场景),你直接套用即可。
